
My Four Steps for a successful cloud deployment - Data
8 February 2019 · Filed in Infrastructure Development BookKeeping the data safe
Twelve factor applications (https://12factor.net/) discourage any form of local data.

Keeping data local to a server may be easier and quicker, but it restricts the options for scaling and providing redundancy for the information.
Some applications, by default, expect local data on the server. In the Cloud, we cannot afford this luxury for two reasons: should we allow local data, it will be lost when the server scales in, or if a fault occurs causing the server to be withdrawn from service.
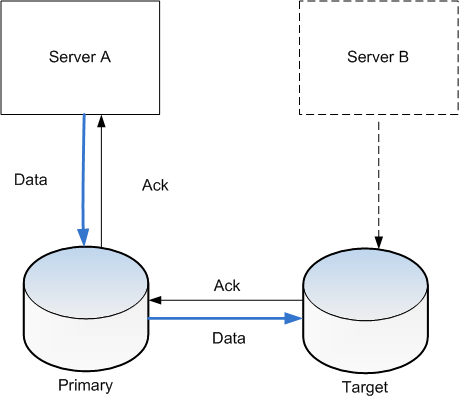
Local data as opposed to shared data is required in some circumstances and must be designed to be disposable. Most services require a database. While this is not stored on the application server and is shared, the server hosting the database service itself needs some form of local data to store that data. Most database systems can be deployed in such a way that it acts as part of a cluster and can survive any one node in that cluster disappearing through scaling or fault. Automated systems should then rebuild a replacement node, degrading the service while this takes place for efficient completion.
Other forms of local data must be configured away from their defaults to enable remote storage.
Application activity and error logs should be streamed to a central logging service. This should be extended to all logging on the server, including system logs and application logs. Not only does this keep the data safe (assuming the logging service is itself a cluster), it also enables easy searching and aggregation of the data for analysis and reporting.
Sometimes overlooked are temporary files used by the server and application. This may be related to a user’s session, but it restricts the user to that one server, making it difficult to scale in.
In some cases, such as WordPress websites, the data directories can only be synchronised if the application can be modified by in-house developers to use shared storage. NFS, Resilio or another syncing solution should be used to preserve and share the data among the application servers.
Keeping data off the application servers and limited to the shared data servers allows for better disaster recovery, enabling a focused effort on the data services for backup and quick service restoration following a component failure.
Having the data in a cluster will protect the service from hardware failure, but a bigger disaster may require relocation of the service entirely. Data backups will enable recovery of data to a different site should the very worse happen. For this reason, Cloud providers have multiple sites or regions, and data can be copied or backed up to another physical location. Having the infrastructure code ready to execute this alternative region is a worthy exercise should the cost of total loss of service justify it.

Regular backup of the data is important for micro restores. This is where only part of the data, otherwise known as a granular restore, will provide a point in time restoration following corruption or malicious data loss. The shorter backup interval reduces the actual data loss endured in these situations, but will take some thought to setup.
Using the Cloud as an offsite backup solution for an existing data centre is more reliable and cheaper than traditional tape and shipping solutions. Tapes are not reliable when it comes to restores, and the process by which the tapes are recovered before restoring can be lengthy, making the Cloud an attractive option.
Excerpt from my new book -
Who moved my servers. Available from Amazon in Paperback and Kindle now.